



sentiment.ai
More powerful sentiment analysis using deep learning models made simple..
See github.io page here https://benwiseman.github.io/sentiment.ai/
Overview
Korn Ferry Institute's AITMI team made sentiment.ai for researchers and tinkerers who want a straight-forward way to
use powerful, open source deep learning models to improve their sentiment analyses. Our approach is relatively simple and out performs the current best offerings on CRAN and even Microsoft's Azure Cognitive Services. Given that we felt the current norm for sentiment analysis isn't quite good enough, we decided to open-source our simplified interface to turn Universal Sentence Encoder embedding vectors into sentiment scores.
We've wrapped a lot of the underlying hassle up to make the process as simple as possible. In addition to just being cool, this approach solves several problems with traditional sentiment analysis, namely:
-
More robust, can handle spelling mitsakes and mixed case, and can be applied to dieciséis (16) languages!
-
Doesn't need a ridged lexicon, rather it matches to an embedding vector (reduces language to a vector of numbers that capture the information, kind of like a PCA). This means you can get scores for words that are not in the lexicon but are similar to existing words!
-
Choose the context for what negative and positive mean using the
sentiment_match()function. For example, you could setpositiveto mean"high quality"and negative to mean"low quality"when looking at product reviews. -
Power Because it draws from language embedding models trained on billions of texts, news articles, and wikipedia entries, it is able to detect things such as "I learned so much on my trip to Hiroshima museum last year!" is associated with something positive and that "What happeded to the people of Hiroshima in 1945" is associated with something negative.
-
The power is yours We've designed
sentiment.aisuch that the community can contribute sentiment models via github. This way, it's easier for the community to work together to make sentiment analysis more reliable! Currently only xgboost and glms (trained on the 512-D embeddings generated with tensorflow) are supported, however in a future update we will add functionality to allow arbitrary sentiment scoring models.
Simple Example
# Load the package
require(sentiment.ai)
require(SentimentAnalysis)
require(sentimentr)
# Only if it's your first ever time
# sentiment.ai.install()
# Initiate the model
# This will create the sentiment.ai.embed model
# Do this so it can be reused without recompiling - especially on GPU!
init_sentiment.ai()
text <- c(
"What a great car. It stopped working after a week.",
"Steve Irwin working to save endangered species",
"Bob Ross teaching people how to paint",
"I saw Adolf Hitler on my vacation in Argentina...",
"the resturant served human flesh",
"the resturant is my favorite!",
"the resturant is my favourite!",
"this restront is my FAVRIT innit!",
"the resturant was my absolute favorite until they gave me food poisoning",
"This fantastic app freezes all the time!",
"I learned so much on my trip to Hiroshima museum last year!",
"What happened to the people of Hiroshima in 1945",
"I had a blast on my trip to Nagasaki",
"The blast in Nagasaki",
"I love watching scary horror movies",
"This package offers so much more nuance to sentiment analysis!",
"you remind me of the babe. What babe? The babe with the power! What power? The power of voodoo. Who do? You do. Do what? Remind me of the babe!"
)
# sentiment.ai
sentiment.ai.score <- sentiment_score(text)
# From Sentiment Analysis
sentimentAnalysis.score <- analyzeSentiment(text)$SentimentQDAP
# From sentimentr
sentimentr.score <- sentiment_by(get_sentences(text), 1:length(text))$ave_sentiment
example <- data.table(target = text,
sentiment.ai = sentiment.ai.score,
sentimentAnalysis = sentimentAnalysis.score,
sentimentr = sentimentr.score)
| target | sentiment.ai | sentimentAnalysis | sentimentr |
|---|---|---|---|
| What a great car. It stopped working after a week. | -0.7 | 0.4 | 0.09 |
| Steve Irwin working to save endangered species | 0.27 | 0.17 | -0.09 |
| Bob Ross teaching people how to paint | 0.28 | 0 | 0 |
| I saw Adolf Hitler on my vacation in Argentina… | -0.29 | 0 | 0.27 |
| the resturant served human flesh | -0.32 | 0.25 | 0 |
| the resturant is my favorite! | 0.8 | 0.5 | 0.34 |
| the resturant is my favourite! | 0.78 | 0 | 0 |
| this restront is my FAVRIT innit! | 0.63 | 0 | 0 |
| the resturant was my absolute favorite until they gave me food poisoning | -0.36 | 0 | 0.12 |
| This fantastic app freezes all the time! | -0.41 | 0.25 | 0.13 |
| I learned so much on my trip to Hiroshima museum last year! | 0.64 | 0 | 0 |
| What happened to the people of Hiroshima in 1945 | -0.58 | 0 | 0 |
| I had a blast on my trip to Nagasaki | 0.73 | -0.33 | -0.13 |
| The blast in Nagasaki | -0.51 | -0.5 | -0.2 |
| I love watching scary horror movies | 0.54 | 0 | -0.31 |
| This package offers so much more nuance to sentiment analysis! | 0.74 | 0 | 0 |
| you remind me of the babe. What babe? The babe with the power! What power? The power of voodoo. Who do? You do. Do what? Remind me of the babe! | 0.55 | 0.3 | -0.05 |
Benchmarks
So, what impact does more robust detection and some broader context have? To test it, in real-world scenarios, we use two datasets/use cases:
-
classifying whether review text from Glassdoor.com is from a
proor acon -
the popular airline tweet sentiment dataset.
We use the default settings for sentimentr, the QDAP dictionary in sentimentAnalysis, and en.large in sentiment.ai. We prefer the use of Kappa to validate classification as it's a less forgiving metric than F1 scores. In both benchmarks sentiment.ai comes out on top by a decent margin!
Note that our testing and tuning was one using comments written in English.

Glassdoor
Applied example, estimating whether the text from a glassdoor.com review is positive or negative. The validation set used here is the same data KFI used in our 2020 SIOP workshop
Note: As a part of KFI's core purpose, sentiment.ai's scoring models were tuned with extra work-related data, hence this is tilted in our favor!
Airline Tweets
Taken from the airline tweet dataset from Kaggle. Classification is positive vs negative (neutral was omitted to remove concerns about cutoff values).
Note: Azure Cognitive Services tune their sentiment model on product reviews, as such this is tilted in favor of Azure!
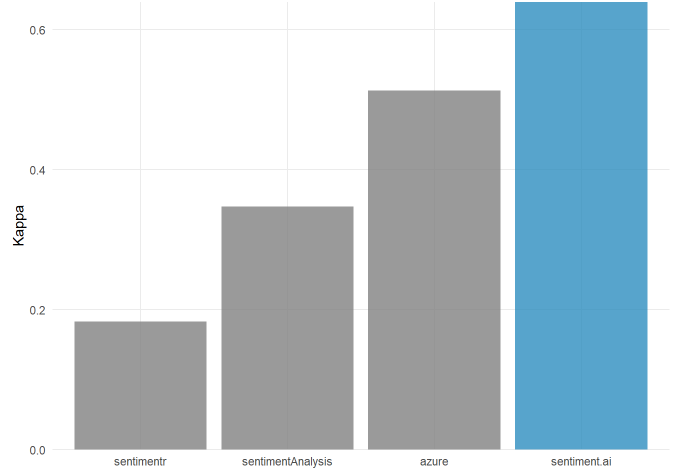
Fierce. It looks like we can be pretty confident that sentiment.ai is a pretty fab alternative to existing packages! Note that over time our sentiment scoring models will get better and better!
Installation & Setup
New installation
After installing sentiment.ai from CRAN, you will need to make sure you have a compatible python environment for tensorflow and tensorflow-text. As this can be a cumbersome experience, we included a
convenience function to install that for you:
install_sentiment.ai()
This only needs to be run the first time you install the package. If you're feeling adventurous, you can modify the environment it will create with the following paramaters:
-
envname- the name of the virtual environment -
method- if you specifically want "conda" or "virtualenv" -
gpu- set to TRUE if you want to run tensorflow-gpu -
python_version- The python version used in the virtual environment -
modules- a names list of the dependencies and versions
# Just leave this as default unless you have a good reason to change it.
# This is quite dependent on specific versions of python moduules
install_sentiment.ai()
Assuming you're using RStudio, it can be helpful to go to tools > global options > python > python interpreter and set your new tensorflow-ready environment as the default interpreter. There'salso an option for automatically setting project-level environments,
Note for GPU installations: you'll need to make sure you have a compatible version of CUDA installed. (Here is a helpful guide to pick your CUDA version)[https://www.tensorflow.org/install/source#gpu]
Initialize
You'll probably want to initialize the language embedding model first if you want to 1) not use the default models, and 2) want to re-apply sentiment scoring without the overhead of preparing the embedding model in memory. Pre-initializing with init_sentiment.ai() is useful for making downstream sentiment scoring and matching run smoothly, especially on GPU.
Technically init_sentiment.ai() will give access to a function called sentiment.ai_embed$f() which uses the pre-trained tensorflow model to embed a vector of text. Power users, the curious, and the damned may want to look in (Helper Functions for an example of this magic)[#power-move].
init_sentiment.ai() has the following optional paramaters:
model
The default Universal Sentence Encoder models available are:
-
en.large(default) use this when your text is in English and you aren't too worried about resource use (i.e. compute time and RAM). This is the most powerful option. -
enuse this when your text is English but your computer can't handle the larger model. -
multi.largeuse this when your text is multi lingual and you aren't too worried about resource use (i.e. compute time and RAM) -
multiuse this when your text is multi lingual but your computer can't handle the larger model. -
A custom tfhub URL - we try to accommodate this if you, for example, want to use an older USE model. This should work but we don't guarantee it!
Example:
# NOTEL In most cases all you need is this:!!
init_sentiment.ai()
# To change the default behavior:
# e.g. to initialise for use on multi lingual comments:
# leave envname alone unless you have a good reason to change it!
init_sentiment.ai(model = "multi.large")
envname
default is envname = "r-sentiment-ai" - only change this if you set a different environment in install_sentiment.ai()
Sentiment Analysis
sentiment_score()
For most use cases, sentiment_score() is the function you'll use.
Returns a vector of sentiment scores. The scores are a rescaled probability of being positive (i.e 0 to 1 scaled as -1 to 1). These are calculated with a secondary scoring model which, by default is from xgboost (a simple GLM is available if for some reason xgboost doesn't work for you!).
The paramaters sentiment_score() takes are:
-
xcharacter vector to analyse. -
model(optional) the name of the embedding model you are using (frominit_sentiment.ai()) -
scoring(optional) the method of scoring sentiment. Options arexgb(default) andglm.xgbis generally more powerful, but requires xgboost (shouldn't be an issue!),glmis faster and almost as powerful (can be better for more 'black and white' use cases) -
scoring_version(optional) "1.0" is the default and (currently) only option. In future this will allow you to use updated/improved models. -
batch_szie(optional) determines how many rows are processed at a time. On CPU this doesn't change much, but can be important if you installed the GPU version. Put simply, small bathes take longer but use less RAM/VRAM, large batches run faster on GPU but could exhaust memopry if too large. Default is 100 (works reliably on an RTX 2080)
Note that if init_sentiment.ai() has not been called before, the function will try to recover by calling it into the default environment. If you're using CUDA/GPU acceleration, you'll see a lot of work happening in the console as the model is compiled on the GPU.
For example:
my_comments <- c("Will you marry me?", "Oh, you're breaking up with me...")
# for English, default is fine
sentiment_score(my_comments)
sentiment_match()
Sometimes you want to classify comments too. For that, we added sentiment_match() which takes a list of positive and negative terms/phrases and returs a dataframe like so:
| Text | Sentiment score | Phrase matched | Class of phrase matched | Similarity to phrase |
|---|---|---|---|---|
| "good stuff" | 0.78 | "something good" | positive |
.30 |
While there are default lists of positive and negative phrases, you can overwrite them with your own. In this way you can quickly make inferences about the class of
comments from your specific domain. The sentiment score is the same as calling sentiment_score() but you also get the most similar phrase, the category of that phrase, and the cosine similarity to the closest phrase.
For example:
my_comments <- c("Will you marry me?", "Oh, you're breaking up with me...")
my_positives <- c("excited", "loving", "content", "happy")
my_negatives <- c("lame", "lonely", "sad", "angry")
my_categories <- list(positive = my_positives, negative = my_negatives)
result <- sentiment_match(x = my_comments, phrases = my_categories)
print(result)
## text sentiment phrase class similarity
## 1: Will you marry me? 0.5393031 loving positive 0.1723714
## 2: Oh, you're breaking up with me... -0.6585207 sad negative 0.1512707
Note Cosine similarity is relative here & longer text will tend to have lower overall similarity to a specific phrase!
Note 2 You can also be tricky and pass in a list of arbitrary themes rather than just positive and negative - in this way sentiment.ai can do arbitrary category matching for you!
Matrix Analysis
cosine()
A light equivilent of text2vec::sim2 that gives pairwise cosine similarity between each row of a matrix.
x1 <- matrix(rnorm(4 * 6),
ncol = 6,
dimnames = list(c("a", "b", "c", "d"), 1:6))
x2 <- matrix(rnorm(4 * 6),
ncol = 6,
dimnames = list(c("w", "x", "y", "z"), 1:6 ))
# to check that it's the same result
# all.equal(cosine(x1, x2), text2vec::sim2(x1, x2))
cosine(x1, x2)
## w x y z
## a -0.1776981 -0.1743733 0.04111033 0.88174300
## b -0.5699782 0.6938432 0.21893192 0.05391341
## c 0.5076042 0.0169079 0.04563749 0.38885764
## d 0.2050958 -0.7644069 -0.74160285 -0.13175003
cosine_match()
This is a helper function to take two matrices, compute their cosine similarity, and give a pairwise ranked table. For example:
cosine_match(target = x1, reference = x2)
## target reference similarity rank
## 1: a w -0.17769814 4
## 2: b w -0.56997820 4
## 3: c w 0.50760421 1
## 4: d w 0.20509577 1
## 5: a x -0.17437331 3
## 6: b x 0.69384318 1
## 7: c x 0.01690790 4
## 8: d x -0.76440688 4
## 9: a y 0.04111033 2
## 10: b y 0.21893192 2
## 11: c y 0.04563749 3
## 12: d y -0.74160285 3
## 13: a z 0.88174300 1
## 14: b z 0.05391341 3
## 15: c z 0.38885764 2
## 16: d z -0.13175003 2
If you filter that to only the rows where rank is 1, you'll have a table of the top matches between target and reference.
embed_text()
As an added bonus of manually calling init_sentiment.ai() you can call embed_text() to turn a vector of text into a numeric embedding matrix (e.g if you want to cluster comments).
For example
# Note, there's some weird behavior when you do this with a single string!
test_target <- c("dogs", "cat", "IT", "computer")
test_ref <- c("animals", "technology")
# Work it!
target_mx <- embed_text(test_target)
ref_mx <- embed_text(test_ref)
ref_mx[1:2, 1:4]
## [,1] [,2] [,3] [,4]
## animals -0.042174224 0.01914462 0.07767479 -0.0362021662
## technology 0.005067721 0.02222563 0.06019276 0.0006833972
# And slay.
result <- cosine_match(target_mx, ref_mx)
result[rank==1] # filtered to top match (with data.table's [] syntax)
## target reference similarity rank
## 1: dogs animals 0.8034535 1
## 2: cat animals 0.6122806 1
## 3: IT technology 0.4383662 1
## 4: computer technology 0.6668407 1
Roadmap
We want to continue making sentiment analysis easier and better, to that end future releases will include:
-
More tuned sentiment scoring models
-
Sentiment scoring that gives probabilities for positive, negative, and neutral.
-
Scoring models from the community (technically this should already be possible)
-
Option for updated python dependencies/environment (requires a lot of testing)
-
Python module
-
Support for GPU on OSX (current limitation with tensorflow on OSX)
-
Support for other embedding models (e.g. infersent)
-
Run language specific benchmarks for multilingual embedding model
Contribute a Model!
Think you can make a better sentiment scoring model? Seeing as I'm far from the sharpest lighbulb out there, you probably can out do me! Simply train a model on text embeddings and add it to the models folder of this repo. Currently we only have support for xgb and glm models (xgb worked really well with minimal faff, and GLMs, saved as simple parameter weights, are super light weight). We will figure out a way to allow custom models, likely with a custom predict script in each model folder, but that's a tomorrow-problem for now.
The models directory contains models used to derrive sentiment after the neural nets have handles the embedding bit.
Directory structure is: model_type/version/
For example: models/xgb/1.0/en.large.xgb is the default scoring model in sentiment_score(x) which is the same as a user passing sentiment_score(model="en.large", scoring="xgb", scoring_version="1.0").When called, sentiment.ai will pull the scoring model from github if it hasn't done so already (default is installed during install_sentiment.ai()) and apply that to the embedded text.
NOTE
If you'd like to contribute a new/better/context specific model, use the same folder structure If it's not a glm or XGB, let us know so we can make it work in find_sentiment_probs()! For non-xgb/glm models, please give an example R script of applying it to a matrix of embedded text so we can add support for it.
We only ask that numeric version (e.g xgb/2.0/...) names be left for official/default models. For community models, the version can be a descriptor (so long as it's a valid file name and URL!) e.g: xgb/jimbojones_imdb1/en.large.xgb This way we can keep it easy for less engaged people who want a package that "just works" while accommodating power users that want custom models
If you have a general purpose model (i.e. trained on a variety of sources, not context specific) that out-performs the default ones, get in touch, we'll test some extra benchmarks, and if it's "just better" we'll add it to become the new official/default (obviously giving you credit!) 
sentiment_score() or sentiment_match().